
在工业生产和质量控制领域,异常检测始终是一个关键问题。传统的异常检测方法通常依赖大量的正常样本进行训练,但在保护用户数据隐私或应用于新生产线时,这些方法往往不适用。零样本异常检测在这种情况下应运而生,其目的是在没有目标类别物体训练数据的情况下,直接进行异常检测。
近日,中科视语和中国科学院自动化研究所的研究团队提出了一种新的零样本异常检测方法——FiLo。 FiLo方法通过细粒度描述和高质量定位模块,在异常检测和异常定位两个方面取得了显著的性能提升,在零样本异常检测工业场景中取得了业内最好性能。

现有的零样本异常检测方法通常依赖于多模态预训练模型的强大泛化能力,通过计算图像特征与手工编写的表示“正常”或“异常”语义的文本特征之间的相似度来检测异常,并根据文本特征和每个图像块特征的相似度来定位异常区域。然而,通用的“异常”描述往往无法精确匹配不同对象类别中的各种异常类型。此外,文本特征与单个图像块的特征的相似性计算难以准确定位具有不同大小和尺度的异常。
中科视语研究团队提出的FiLo方法为了解决现有零样本异常检测方法在异常检测和异常定位两个方面存在的问题,提出了两个有机结合的模块:自适应学习的细粒度描述模块(FG-Des)和位置增强的高质量定位模块(HQ-Loc):
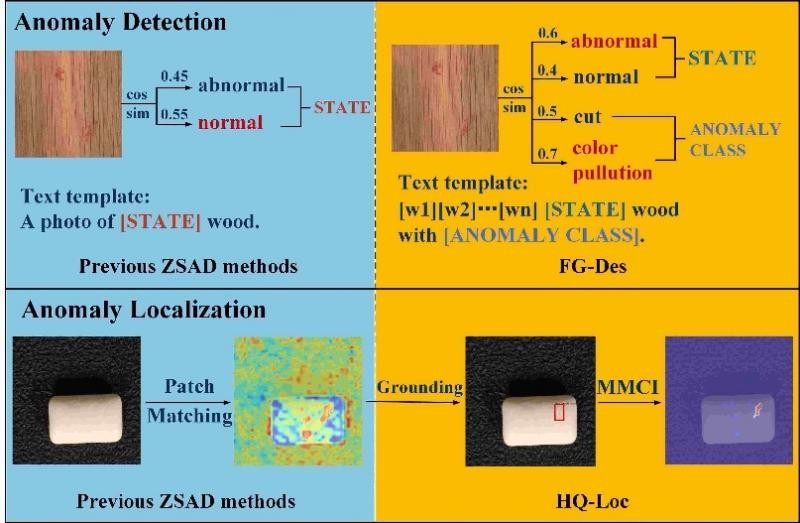
自适应学习的细粒度描述模块(FG-Des)主要利用大语言模型(LLMs)的强大知识来生成每个物体类别可能出现的细粒度异常类型,并采用自适应学习的文本模板替代手工编写的文本内容,提高了异常检测的准确性和可解释性。
位置增强的高质量定位模块(HQ-Loc)利用Grounding DINO进行初步定位,并通过位置增强的文本提示和多尺度、多形状的跨模态交互模块(MMCI)来准确定位不同大小和形状的异常。
结合了 FG-Des 和 HQ-Loc 两个模块的 FiLo 方法的整体结构如下图所示:

FiLo首先通过大语言模型(LLMs)生成每个类别可能存在的细粒度异常类型列表,然后将细粒度异常描述填入可学习的文本模板中,通过 CLIP 文本编码器后得到表示“正常”和“异常”语义的文本特征。与此同时,FiLo还将待检测图像和大语言模型生成的细粒度异常描述内容输入到Grounding DINO中,以获得初步的异常定位框,并将初步定位框的位置信息也添加到文本特征中。
接下来,FiLo将待检测图像输入到CLIP图像编码器以提取中间层特征,这些特征通过多尺度、多形状的跨模态交互模块(MMCI)与含有位置信息的文本特征交互,生成异常分数图。最后综合各中间层的异常分数图,即可得到最终的异常图和全局异常得分。
通过这种方法,FiLo能够充分利用LLMs的强大先验知识和Grounding DINO的初步定位能力,再结合MMCI模块的多尺度、多形状特征交互,有效提升了异常检测的准确性和精确定位的能力。
基于上述方法结构,FiLo研究团队在目前流行的 MVTec-AD和VisA两个工业异常检测数据集上进行了实验,与现有零样本异常检测方法相比,FiLo取得了最先进的性能,实验结果如下表所示:

下图还展示了FiLo在一些实例上的异常检测和定位结果,可以发现相比于 CLIP 的原始输出,经过 Grounding DINO 的定位框筛选和MMCI的多尺度交互后,FiLo 能够更加准确地定位出异常位置。
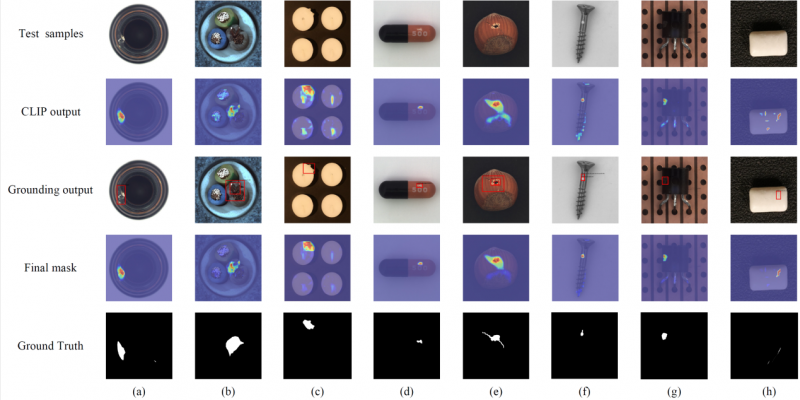
除此之外,通过查看与图像特征最相似的细粒度异常描述中的内容,我们还可以知道图像中存在的具体异常种类,为模型的判断提供了依据,提高了模型决策的可信度和可解释性。

FiLo论文已经被人工智能和多媒体领域顶级会议 ACM MM 2024 接收,论文预印版已发布于 Arxiv 上,并开源了相关代码。
研究团队认为,现有异常检测方法往往只注重判断图像中是否含有异常,而不重视异常的具体内容,通过借助大语言模型的丰富知识,后续研究可以增强异常检测方法对具体异常类型的判断,增加方法的实用性和可信度。
论文地址:[2404.13671] FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization
https://arxiv.org/abs/2404.13671
代码地址:
https://github.com/CASIA-IVA-Lab/FiLo
-
周大福人寿「闪耀传承」储蓄寿险计划 助客户增值财富 灵活规划传承来源 CTF LIFE 周大福人寿「闪耀传承」储蓄寿险计划 助客户增值财富 灵活规划传承 - 联手大湾区医疗集团提供个人化全面健康检查及升级医疗保障 香港, 20242024-07-30
-
成果速递丨ACM MM 2024:中科视语提出FiLo,实现工业场景零样本异常检测新突破在工业生产和质量控制领域,异常检测始终是一个关键问题。传统的异常检测方法通常依赖大量的正常样本进行训练,但在保护用户数据隐私或应用于新生产线时,这些方法往往2024-07-30
-
陈聚宝:真品靠谱 假货可怕 抵制假货 就是保护科技创新陈聚宝:真品靠谱 假货可怕 抵制假货 就是保护科技创新 近日,一则由爱奇国际发出的所谓“重要通知”的谣言,要在事实面前不攻自破,内容中提到“蒋教授已在2022年发2024-07-30
-
联合企业集团——易腾云云电脑系统延迟突破6毫秒技术新闻发布会成功举行7月29日,由联合企业集团、纽扣数字智能联合主办,深圳市智能终端产业协会协办的“易腾云云电脑系统延迟突破6毫秒技术新闻发布会”在中国深圳隆重举行。本次活动2024-07-30
-
AWC 2024引爆未来出行,重塑全球汽车产业版图!2024年,汽车行业正处于转型升级的关键时刻,新能源和智能网联汽车的崛起正在重新定义市场格局。回顾上半年,汽车行业主要经济指标呈现增长态势,新能源汽车产销持续快速2024-07-30